OpenBMB介绍
OPenBMB介绍
OpenBMB全称为Open Lab for Big Model Base,旨在打造大规模预训练语言模型库与相关工具,加速百亿级以上大模型的训练、微调与推理,降低大模型使用门槛,与国内外开发者共同努力形成大模型开源社区,推动大模型生态发展,实现大模型的标准化、普及化和实用化,让大模型飞入千家万户。
OpenBMB能力体系
谋定而动,OpenBMB将从数据、工具、模型、协议四个层面构建应用便捷、能力全面、使用规范的大规模预训练模型库。

OpenBMB能力体系具体包括:
数据层
构建大规模数据自动收集、自动清洗、高效存储模块与相关工具,为大模型训练提供数据支持。
工具层
聚焦模型训练、模型微调、模型推理、模型应用四个大模型主要场景,推出配套开源工具包,提升各环节效率,降低计算和人力成本。
模型层
构建OpenBMB工具支持的开源大模型库,包括BERT、GPT、T5等通用大模型和CPM、EVA、GLM等悟道开源大模型,并不断完善添加新模型,形成覆盖全面的模型能力。
OpenBMB开发的模型:
CPM:中国首个中文大模型,2020年11月发布,26亿参数规模。
CPM2:CPM大模型第2版,2021年6月发布。110亿参数规模,基于MoE架构可达到1980亿。
CPM-Ant (2022/05/29-2022/08/05) :最新的百亿大模型训练直播项目CPM-Live的第一期模型 CPM-Ant。 CPM-Ant是一个开源的中文预训练语言模型,拥有10B参数。code
CPM-Bee(2022/10/13-2023/05/27):一个完全开源、允许商用的百亿参数中英文基座模型,也是CPM-Live训练的第二个里程碑。它采用Transformer自回归架构(auto-regressive),在超万亿(trillion)高质量语料上进行预训练,拥有强大的基础能力。CPM-Bee 一网打尽多种能力,可以准确地进行语义理解,高效完成各类基础任务,包括:文字填空、文本生成、翻译、问答、评分预测、文本选择题 等等。考虑到用户使用模型的易用性,我们在预训练阶段将模型的输入输出设计成了 JSON 结构化形式,用户只需调整不同任务字段,就可以完成各类任务。
2
3
4
5
6
7
8
9
10
"翻译": {"input": "北京是中国的首都", "prompt": "中翻英", "<ans>": ""}
"评分预测": {"input":"之前多次聚餐都选择这里,有各种大小的包房同时能容纳很多人,
环境好有特色还有表演,整体聚餐氛围一下被带动起来。现在由于炭火改成了电烤羊,
口感真的不如从前,不过其他菜品都还是不错,烤羊剩下的拆骨肉最后还能再加工一下椒盐的也很好吃。",
"question":"评分是多少?(1-5)","<ans>":""}
"选择题": {"input": "父母都希望自己的孩子诚实、勇敢、有礼貌。要想让孩子成为这样的人
,父母首先得从自己做起,要是连自己都做不到,又怎能要求孩子做到呢?",
"options": {"<option_0>": "少提要求", "<option_1>": "降低标准", "<option_2>": "自己先做好", "<option_3>": "让孩子拿主意"},
"question": "教育孩子时,父母应该:", "<ans>": ""}
协议层
发布通用模型许可协议,规范与保护大模型发布使用过程中发布者与使用者权利与义务,目前协议初稿已经开源(https://www.openbmb.org/license)

基于发起人团队前期工作,OpenBMB设计了大模型全流程研发框架,并初步开发了相关工具,这些工具各司其职、相互协作,共同实现大模型从训练、微调到推理的全流程高效计算。
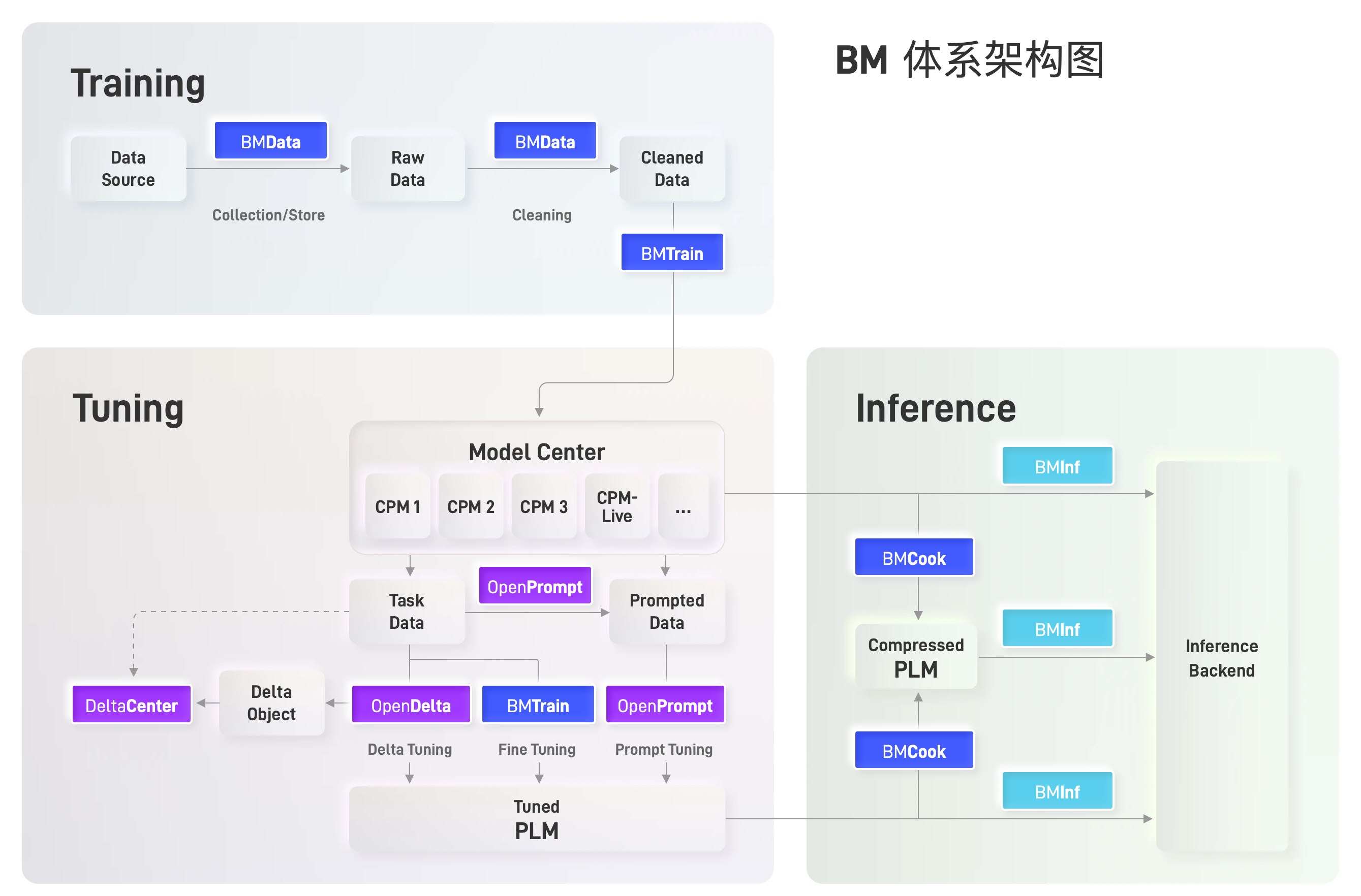
OpenBMB工具
OpenBMB模型训练套件
BMData:大模型“原料”收集器
BMData进行高质量数据清洗、处理与存储,为大模型训练提供全面、综合的数据支持。
注:还在开发中~
BMTrain:大模型训练“发动机”
大模型训练“发动机”。BMTrain进行高效的大模型预训练与微调。与DeepSpeed等框架相比,BMTrain训练模型成本可节省90%。
BMTrain介绍,BMTrain技术原理浅析,BMTrain code和BMTrain’s Documentation
为什么需要BMTrain?
算力成本高
模型巨大的参数量无法在单张显卡中完成存储与计算。OpenAI 训练 GPT-3 (约1750亿参数)使用了上千张 GPU,Google 训练 PaLM (约5000亿参数)使用了六千片 TPU,带来了高昂的训练成本,配置规模庞大的计算集群也十分困难。
编程难度大
为了利用分布式算力加速大模型的训练和微调,程序员需要编写复杂的分布式程序来驱动大模型。现有的框架(如DeepSpeed)已经能够较好地支持模型的分布式训练,但依然需要用户进行较为复杂的编程与配置。
计算速度低
在分布式训练框架中,不同计算节点之间需要频繁地进行通信,此时通信带宽往往成为模型的训练瓶颈,若不能合理设计通信策略并进行有效且正确的代码实现,训练模型所需的时间将被大大延长,不能充分发挥计算设备的潜力。
BMTrian的目的是什么?
高效率
作为大模型训练的 “发动机”,BMTrain 能够在任意数量的 GPU 上进行高效的大模型预训练与微调,最优化分布式框架的通信开销,在超大规模模型训练场景下与 DeepSpeed 等框架相比可以节省 90% 的算力成本。

低资源
不同于OpenAI、Google 等机构的算力条件,为了让更多实验室和企业也能够训练大模型,我们致力于在保持高效计算前提下最小化大模型的算力需求,实现单张消费级显卡全参数微调 BERT-Large,8 台 A100 小集群训练 GPT-3,进一步降低大模型的算力门槛。
在消费级显卡2080Ti上,BMTrain可以实现BERT-Large的微调(3亿参数,样本长度 512)。

在较高规模算力条件下(显卡为A100 40GB,NVLink,400Gbps IB),BMTrain可以训练超大规模的 GPT-3(1750亿参数)。

使用BMTrain或者ColossalAI,64卡A100跑完GPT-3的300B token大概需要2年,服务器与显卡租金大约900万左右。根据我们的实验估算,使用128张A100时,单卡吞吐量可以提升2.5倍以上,6个月可以跑完GPT-3,服务器租金大约500万左右。虽然训练出GPT-3的成本依然高昂,但与GPT-3的1200万美元相比,成本仍然节约了90%以上。
可扩展
在编程难度方面,我们致力做最简洁最有效的封装,仅使用少量的代码替换,即可达到与原生 PyTorch 一致的编程体验,一键安装工具包降低配置难度,让大模型真正飞入千家万户。BMTrain 与 ModelCenter 共同组成了高效分布式预训练框架,适用于任意的 Transformer 结构,可以在较少数量的 GPU 上训练,且高度兼容 PyTorch、Transformers 库,学习成本极低。目前我们已经支持了常用的英文模型如 BERT、GPT、T5、RoBERTa 以及中文模型如 CPM-1、CPM-2 等。

如何去实现?
- 分析GPU显存在哪里消耗?
- 理解多张显卡合作模式
核心技术
这块还要继续深入了解
- ZeRO-3 Optimization
- Overlap Communication and Computation
- CPU Offload
详见Introduction to Core Technology — BMTrain documentation
BMCook:大模型“瘦身”工具库
BMCook进行大模型高效压缩,提升运行效率。通过量化、剪枝、蒸馏、专家化等算法组合,可保持原模型90%+效果,模型推理加速10倍
github’s code,BMCook’s documentation
为什么需要BMCook?
PLM规模爆炸增长
PLM的模型规模一直在以每年约10倍的速度增长
| Date | Organization | Name | Model Size | Data Size | Time |
|---|---|---|---|---|---|
| 2018.6 | OpenAI | GPT | 110M | 4GB | 3 Days |
| 2018.10 | BERT | 330M | 16GB | 50 Days | |
| 2019.2 | OpenAI | GPT-2 | 1.5B | 40GB | 200 Days |
| 2019.7 | RoBERTa | 330M | 160GB | 3 Years | |
| 2019.10 | T5 | 11B | 800GB | 66 Years | |
| 2020.6 | OpenAI | GPT-3 | 175B | 2TB | 355 Years |
巨大的计算成本
不断增长的规模伴随着巨大的计算开销
限制大型PLM在现实世界场景中的应用
导致大量碳排放
目标
- Model Compression:将大模型压缩为小模型,以满足现实世界场景的需求。目的希望讲大模型压缩成小规模模型,同时需要基本上继承大模型的能力,能在现实场景应用,用更普通设备计算,希望在一张显卡上计算
现存方法
需要深入了解
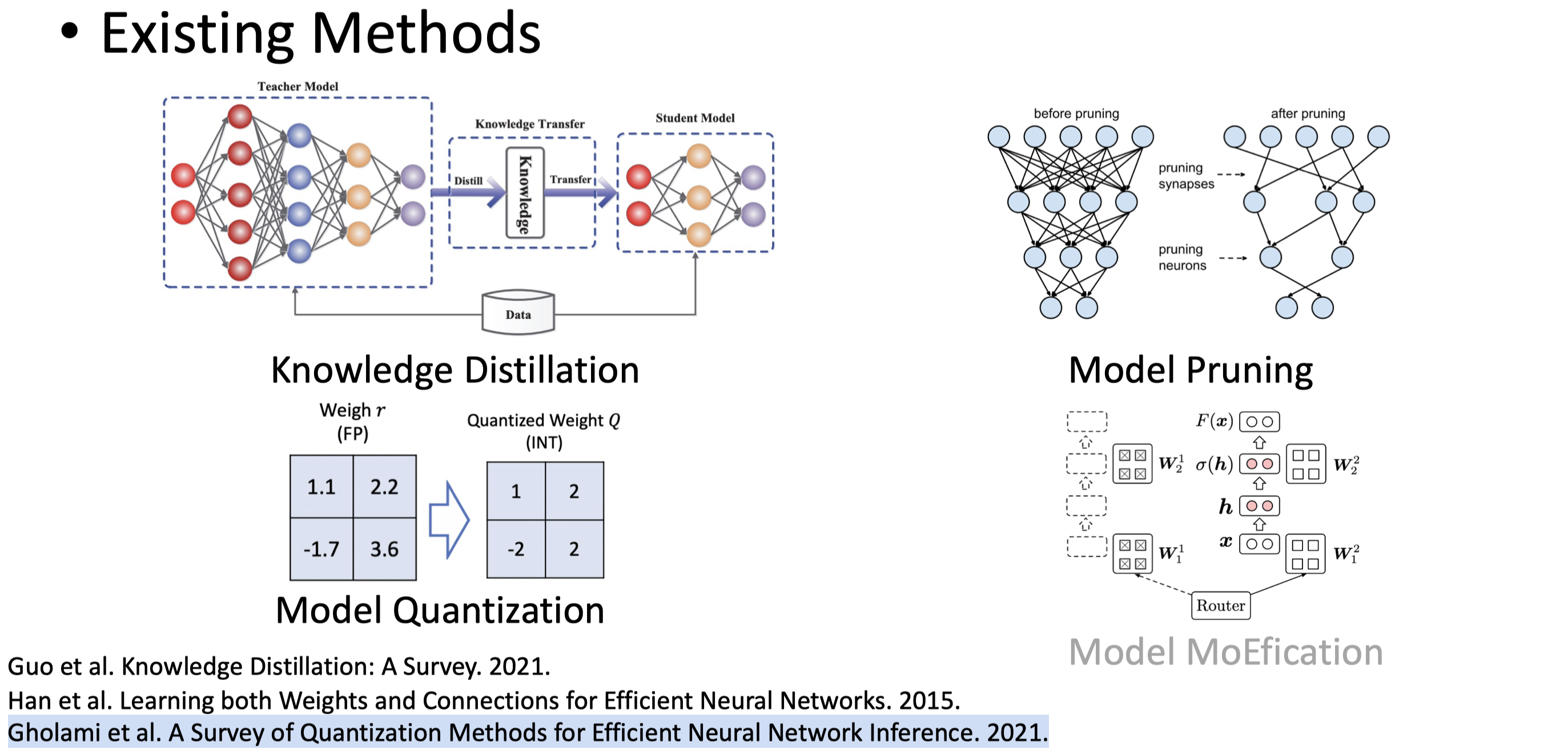
Model Pruning-2015:剪枝50%参数,可加速1倍
Model Pruning:修剪通过删除不重要的参数来压缩神经网络。根据修剪的粒度,它被分为结构化修剪和非结构化修剪。在这个工具包中,我们实现了两种修剪方法。对于非结构化修剪,我们实现了2:4的稀疏模式来利用NVIDIA GPU的TensorCore,这带来了1倍的速度。
Model Quantization-2021:提升4倍运算速度 ,使用1/4存储空间
Model Quantization:量化通过以低位精度表示参数,将神经网络压缩成更小的尺寸,例如8位整数(INT8)而不是32位浮点(FP32)。它通过以低精度存储参数和以低精度加速计算来减少内存占用空间。在这个工具包中,我们针对量化感知训练,在训练期间模拟低精度的计算,使模型参数适应低精度。我们将模型中的所有线性变换量化,这些变换涵盖了变压器计算的90%以上。对于令牌嵌入和注意力矩阵,我们仍然使用浮点,这确保了良好的性能,计算成本很小。
Model MoEfication-2022:减少80%线性层参数,可加速1倍
MoEfication利用了PLM中的稀疏激活现象,并将前馈网络拆分为几个小型专家网络,以进行PLM的条件计算。有关更多详细信息,请参阅本文。
Knowledge Distillation-2021:为以上模块提供更优监督型号
Knowledge Distillation:知识蒸馏旨在缓解模型压缩导致的性能下降。与传统的预训练相比,它提供了更具信息性的训练目标。在这个工具包中,我们基于输出逻辑、中间隐藏状态和注意力矩阵实现知识蒸馏损失。在实践中,我们发现基于输出 logits 的损失就足够了。

优点
任意组合
受益于解耦合的实现方式,我们可以任意组合压缩方法尽可能地加速模型。


OpenBMB模型推理套件
BMinf-千元级显卡玩转大模型推理
OpenBMB核心模块,用于高效推理,可于Nvidia GTX 1060 6G显卡运行百亿大模型。
BMinf-paper,BMInf-blog,BMInf-github和BMInf-Document
背景
最近在工业界与学术界,最热门的方向莫过于预训练语言模型。而具有百亿乃至千亿参数的大规模预训练语言模型,更是业界与学术界发力的热点。
但现在大模型的应用却有着较高的门槛,排队申请或需要付费的API、较长的模型响应速度、推理所需要的较为昂贵的算力资源……种种因素都影响着大模型的快速应用与落地。对于普通的研究者与开发者来说,大模型可以说是看得见,却很难摸得着。
由OpenBMB团队与北京智源研究院联合发布的一款低资源大模型推理工具包BMInf,一面世就获得了广大发烧友的喜爱,该项目已在GitHub获得237个Star,并且论文已被ACL 2022收录。下面,我将带领大家重温BMInf。

难题 :
所需硬件要求高:每个demo需要4*A100s
太慢:一次需求需要十秒
昂贵:4*A100s 是1200元每天

另外一个思路:公共服务器至本地服务器。希望至少能在GTX1060运行

优点:
硬件友好。BMInf最低支持在NVIDIA GTX 1060单卡运行百亿大模型,使用更好的GPU会有更好的运行性能。在显存支持进行大模型推理的情况下(如V100或A100显卡),BMInf的实现较现有PyTorch版本仍有较大性能提升。
开源共享。模型参数开源共享,用户在本地即可部署运行,无需访问或申请API。
能力全面。支持生成模型CPM1 [1]、通用模型CPM2 [2]、对话模型EVA [3],模型能力覆盖文本补全、文本生成与对话。
模型升级。基于持续学习推出百亿模型新升级CPM2.1,文本生成能力大幅提高
应用便捷。基于工具包可以快速开发大模型相关下游应用。
背后技术:
深入了解
模型压缩:如果不做任何特殊处理,运行一个22GB的模型需要一块显存大小至少为22GB的GPU。满足这样条件的GPU通常是很昂贵的(例如 V100 32GB, A100, RTX 3090,市场价均超过2万元),为了能让模型在更小显存的GPU上运行,开发者在保留模型原有结构的基础上,将模型中占比最大的线性层参数(占比99%)从16比特浮点数转换为了int8格式。为了让压缩后的模型更贴近于原来的效果,开发者在将参数转换后进行了几千次迭代的微调让模型适应新的参数精度,微调后的模型基本上已经达到了和原始模型相近的能力。在具体的PPL指标中,压缩后的模型相比于压缩前只相差了5~10左右。
显存调度:在使用了模型压缩技术后,原本大小22GB的模型被压缩到了11GB,对于NVIDIA旗舰级别GPU来说(如GTX 1080Ti, RTX 2080Ti),11GB显存已经是可以摸到的门槛了,但是考虑到在推理过程中还需要使用一些额外的空间来存储中间变量,这样的显存容量依然不够。另外,能够拥有这样旗舰级别显卡的个人用户仍然较少,像GTX 1060 6G这样甜点级的GPU有着更加广泛的市场占有率。
要让一个11GB大小的模型运行在显存容量只有6GB的GPU上,开发者使用了显存和内存的优化与调度技术。在运行过程中将需要用于进行运算的模型参数提前准备好并放置在显存中,而对于暂时不需要用到的部分,则放置在CPU内存中。

性能测试

支持模型
BMInf目前支持下列模型:
- CPM2.1. CPM2.1是CPM2的升级版本。CPM2是一个拥有110亿参数的通用中文预训练语言模型。基于CPM2,CPM2.1新增了一个生成式的预训练任务并基于持续学习范式进行训练。实验结果证明CPM2.1比CPM2具有更好的生成能力。
- CPM1. CPM1是一个拥有26亿参数的生成式中文预训练语言模型。CPM1的模型架构与GPT 类似,它能够被应用于广泛的自然语言处理任务,如对话、文章生成、完形填空和语言理解。
- EVA. EVA 是一个有着28亿参数的中文预训练对话模型。EVA在很多对话任务上表现优异,尤其是在多轮人机交互对话任务上。
除了这些模型,我们目前致力于导入更多的预训练语言模型,尤其是大规模预训练语言模型。我们欢迎每一位贡献者通过提交issue来添加他们的模型。
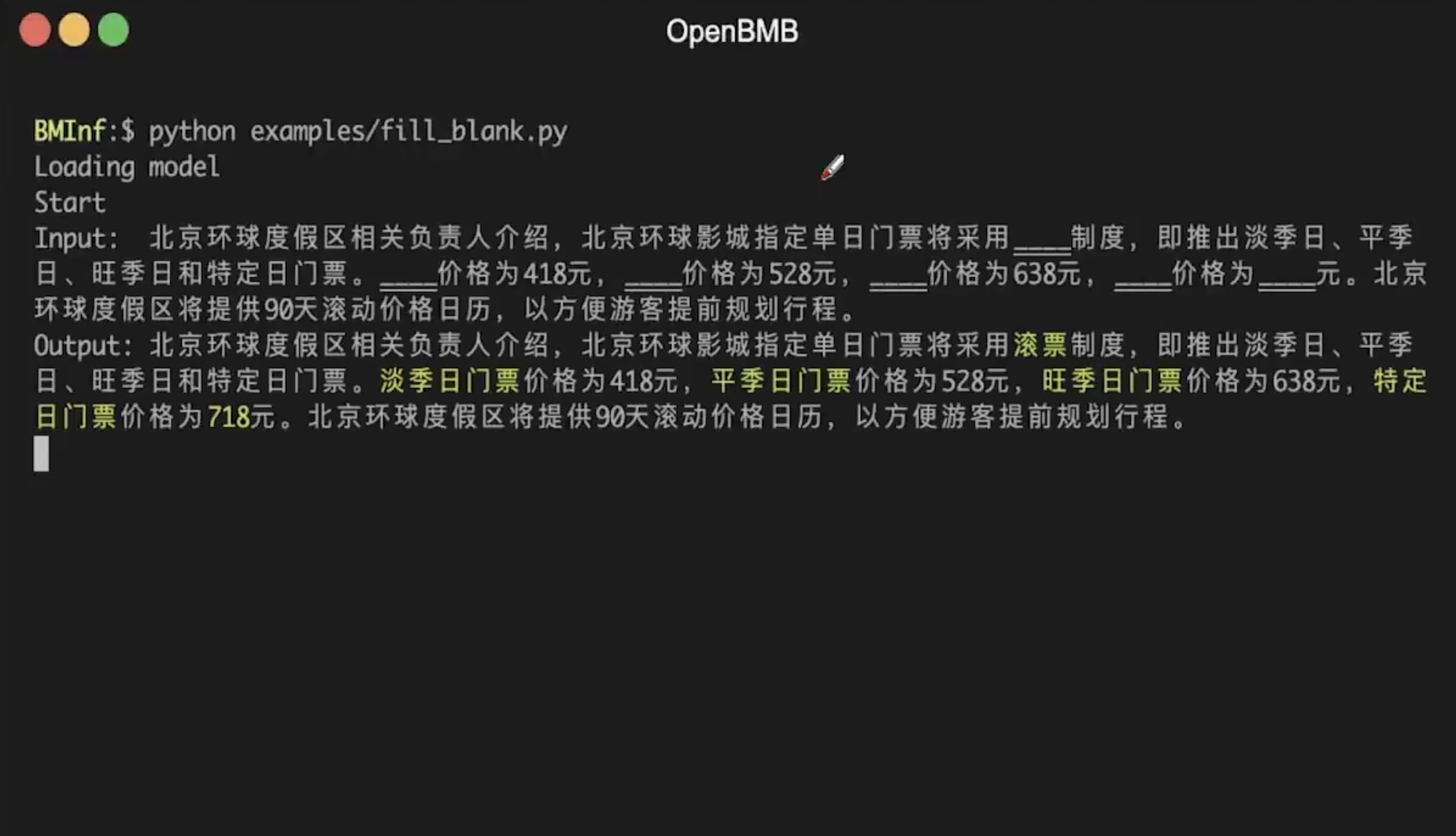
实例

OpenBMB模型微调套件
OpenPrompt-大模型提示学习利器
OpenPrompt是一个统一范式的prompt-learning工具包
OpenPrompt提供统一接口的提示学习模版语言, 它的组合性和模块化可以让你轻松部署提示学习方法以驱动大模型。2021年发布以来在GitHub获得1.3k星标,每周访问量10K+。
OpenBMB核心模块,用于提示学习微调,获得ACL 2022最佳演示论文奖。
OpenPrompt-paper,Prompt-Learning视频,OpenPromp-github和OpenPrompt Documentation
背景介绍:
Prompt-learning范式的崛起
最近一段时间,一种新的驱动大模型的范式受到了NLP界的广泛关注,它就是提示学习(prompt-learning,又prompt-tuning),它将对输入的文本按照模板进行特殊的处理,把任务重构成一个“预训练任务”。比如,在一个情感分类任务中,我们需要判断“这电影让我感觉浪费生命”这句话的情感是“正向”还是“负向”,则可以用模板把分类问题转化为一个“完形填空”问题:“这电影让我感觉浪费生命,它真的很[MASK]”,这里的输出是“棒”和“糟”来对应二分类。研究发现,在训练样本较少时,prompt-learning的表现会异常优异,它能够有效地建立起预训练和模型适配之间的桥梁。更重要地,它是我们驱动超大模型(如无法直接微调的千亿参数模型)的有效手段。
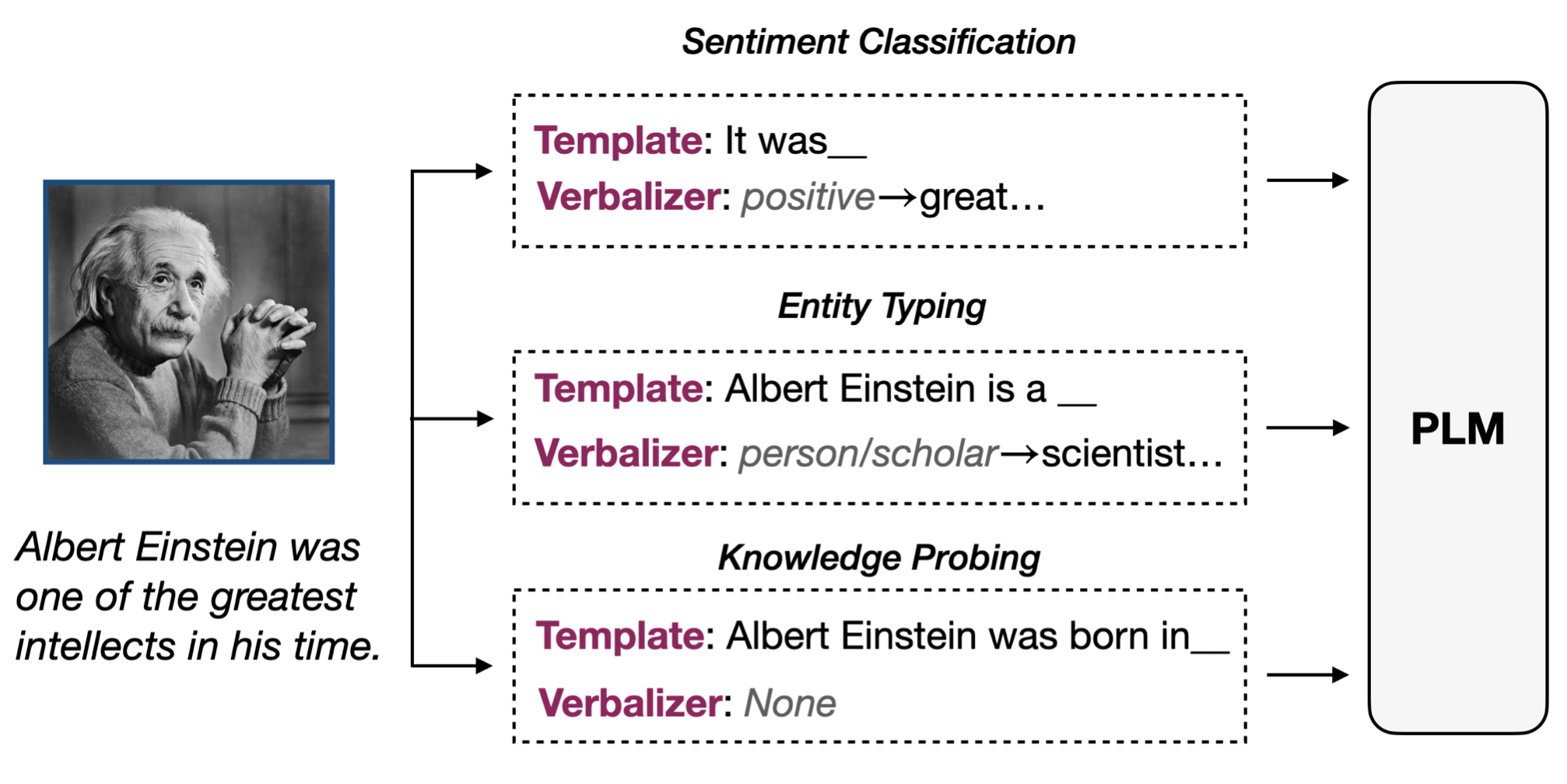
简单的例子

OpenPrompt工具包结构图
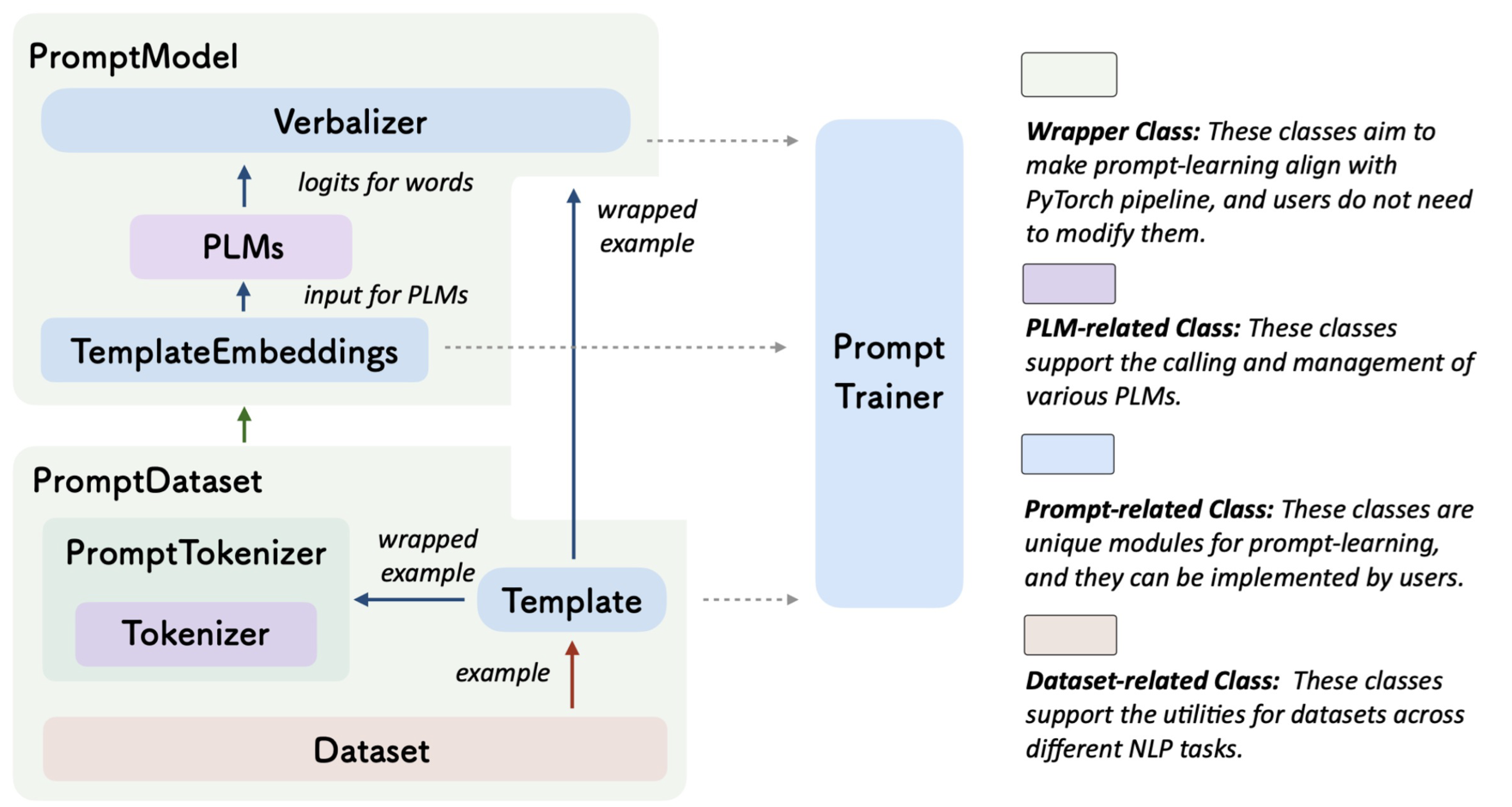
事实上,一个prompt-learning流程是预训练任务、当前任务、人类先验知识、模型架构的综合过程。
我们可能在具体实现中遇到各种细节问题,如:
该用什么类型的模型,是MLM还是seq2seq?
该用什么参数级别的模型,是亿级、十亿级还是百亿级以上的超大模型?
- 该使用什么模板?
- 是人工构建还是用soft tokens随机初始化?
- 该如何构建标签到词表的映射?
- 该使用什么训练手段?
模块语言:
OpenPrompt中的模板语言支持自由地组合包括文本模板和软模板的各类字符,并支持字符级别的属性定制。

优点
- 易用性。基于OpenPrompt工具包,使用者可以快速根据不同任务部署prompt-learning框架。
- 组合性。从前的prompt-learning研究往往只实验了一种设定,在OpenPrompt的模块化支持下,使用者可以自由地将模型、模板、标词映射进行组合,从而进行更加全面的实验。
- 拓展性。OpenPrompt具有灵活的可拓展性,使用者可以轻松地在其之上完成进阶开发,让你的prompt-learning研究快人一步!
一些实现的prompt-learning工作
OpenDelta:“小”参数撬动“大”模型
OpenDelta进行参数高效的大模型微调,仅更新极少参数(小于5%)即可达到全参数微调的效果。
OpenDelta-paper,OpenDelta:Delta Tuning-github,Delta Tuning-blog和OpenDelta’s documentation
DeltaTuning 的提出背景
需深入了解deltatuning的原理
2018年预训练语言模型(PLM)横空出世,目前“预训练-微调”方法已成为NLP任务的主流范式。在这个新范式下,我们可以利用大规模无标注数据通过自监督学习预训练语言大模型,得到基础模型,再利用下游任务的有标注数据进行有监督学习微调模型参数,实现下游任务的适配。最近爆火的ChatGPT就是大模型的代表,越来越多的实验和实践表明:规模越大的模型不仅在已知任务上有着更好的表现,同时展现出完成更复杂的未知任务的强大泛化能力。

然而,更大的模型也在应用上面临着更大的挑战,传统方法对超大规模的预训练模型进行全参数微调的过程会消耗大量的GPU计算资源与存储资源,巨大的成本令人望而却步。论文统计选取了1000篇来自最近五个NLP会议的论文,发现尽管预训练模型已经成为了主流范式,但涉及大模型的论文却寥寥无几。
为了应对该挑战,参数高效微调(Parameter-efficient Fine-tuning)方法逐渐受到关注。与全参数微调相比,参数高效微调方法冻结预训练模型99%以上的参数,仅利用少量下游任务数据微调少于1%模型规模的参数,作为模型插件实现大模型对下游任务的适配,达到媲美全参数微调的性能,并显著降了微调过程的计算和存储开销。
DeltaTuning:方法与分析
我们的研究提出,参数高效微调方法的本质是在对“增量参数”(Delta Parameters)进行调整,因此将此类方法命名为“增量微调”(Delta Tuning),其中“delta”是一个经常用于表示变化的数学符号,被借用来指在训练中“改变”的参数部分。研究基于统一的分析框架对增量微调现有方法进行梳理总结,将现有方法分为三类:添加式(Addition-based)、指定式(Specification-based)和重参数化(Reparameterization-based)方法。为了指导后续的模型架构和算法设计,研究还进一步从参数优化和最优控制两个角度,提出了增量微调的理论框架,为探索和解释增量微调的内在机理提供了可行方案。

Delta thus means a small fraction $\Delta \Theta$ of parameters besides the pretrained models $\Theta_0$.
DeltaTuning的理论视角
Delta Tuning本质上是否有共通之处?我们认为,Delta Tuning方法不仅具有很高的实用价值,更具有深远的理论意义,它们似乎都在不约而同地证明一件事情:即大模型的适配过程似乎是一个非常低消耗的过程(相比于预训练),它可以通过非常少的数据和非常少的参数调整来完成。Delta Tuning的成功启发我们去进一步地探索模型适配背后的理论框架,本文提出了优化和最优控制两个视角的框架去对Delta Tuning进行理论层面的阐释。
从优化角度,我们分析Delta Tuning的效果并讨论了在低维假设下的一些Delta Tuning方法的设计。使用Delta Tuning后,目标函数及其所依赖的参数都可能会发生改变。对新的目标函数,仅优化其与Delta Tuning有关的参数,如果初值足够好,在一定假设意义下模型的性能不会有大的损害。但是为了确保Delta Tuning的有效性,有必要去开发问题的结构来设计这个新的目标函数。其出发点是利用问题内在的低维特性。一般而言,在实践中有两种思路被证明是有用的:一,在特定的低维的子空间内寻找解向量;二,在特定的低维的函数空间内近似目标函数。从最优控制角度,基于以往的从最优控制角度解释深度学习的理论,我们揭示了Delta Tuning可以看作寻找最优控制器的过程。
我们的分析可以启发新颖的Delta Tuning方法的设计,我们还证明了Delta参数 对 PLM 的干预等同于控制器的设计。通过应用控制器设计 的理论,我们期望提出更多具有理论保证的 Delta Tuning 方法,即设计的 delta 结构在充分激发PLM的情况下具有原则上的可解释性。
DeltaTuning:全方位实验
我们选择了超过100个自然语言处理任务,对主流增量微调方法进行了全面细致的性能比较和分析,得出多项重要结论,例如:
- 基础模型随着参数规模的不断增大,在性能显著提高的同时,不同增量微调方法的差异急剧减少,最少仅需要优化万分之八的模型参数即可完成适配;
不同增量微调方法可以进行并行或者串行的组合从而达到更优的性能,表明了分布在模型参数空间中的智能能力可以进行组合和泛化;
增量微调方法具备良好的任务级别的迁移能力,完成特定任务的“能力”可以表示为轻量级参数化的形式,可以在不同基础模型和不同用户之间共享。
以上研究表明,增量微调是基础模型的重要特性,上述结论将加深对基础模型的认识,为其创新研究与应用提供重要支撑。
DeltaTuning的应用
快速训练与存储空间节省。Transformer 模型虽然本质上是可并行化的,但由于其庞大的规模,训练起来非常缓慢。尽管 Delta Tuning 的收敛速度可能比传统的全参数微调慢,但随着反向传播期间可微调参数的计算量显著减少,Delta Tuning 的训练速度也得到了显著提升。前人工作已经验证了,使用 Adapter 进行下游调优可以将训练时间减少到 40%,同时保持与全参数微调相当的性能。由于轻量的特性,训练得到的 Delta 参数还可以节省存储空间,从而方便在从业者之间共享,促进知识迁移。
多任务学习。构建通用的人工智能系统一直是研究人员的目标。最近,超大型 PLM (例如 GPT-3) 已经展示了同时拟合不同数据分布和促进各种任务的下游性能的惊人能力。因此,在大规模预训练时代,多任务学习受到越来越多的关注。作为全参数微调方法的有效替代,Delta Tuning 具有出色的多任务学习能力,同时保持相对较低的额外存储。成功的应用包括多语言学习、阅读理解等。此外,Delta Tuning也有望作为持续学习中灾难性遗忘的潜在解决方案。
中心化模型服务和并行计算。超大型 PLM 通常作为服务发布,即用户通过与模型提供者公布的 API 交互来使用大模型,而不是本地存储大模型。考虑到用户和服务提供商之间难以承受的通信成本,由于其轻量级的特性,Delta Tuning 显然是比传统全参数微调更具竞争力的选择。一方面,服务提供商可以支持训练多个用户所需的下游任务,同时消耗更少的计算和存储空间。此外,考虑到一些 Delta Tuning 算法本质上是可并行的(例如 Prompt Tuning 和 Prefix-Tuning等),因此 Delta Tuning 可以允许在同一个 batch 中并行训练/测试来自多个用户的样本(In-batch Parallel Computing)。最近的工作还表明,大多数 Delta Tuning 方法,如果本质上不能并行化,也可以通过一些方法修改以支持并行计算。另一方面,当中心的达模型的梯度对用户不可用时,Delta Tuning 仍然能够通过无梯度的黑盒算法,仅调用模型推理 API 来优化大型 PLM。
为什么选择OpenDelta?
Clean: No need to edit the backbone PTM’s codes.
Simple: Migrating from full-model tuning to delta-tuning needs as little as 3 lines of codes.
Sustainable: Most evolution in external library doesn’t require a new OpenDelta.
Extendable: Various PTMs can share the same delta-tuning codes.
Flexible: Able to apply delta-tuning to (almost) any position of the PTMs.
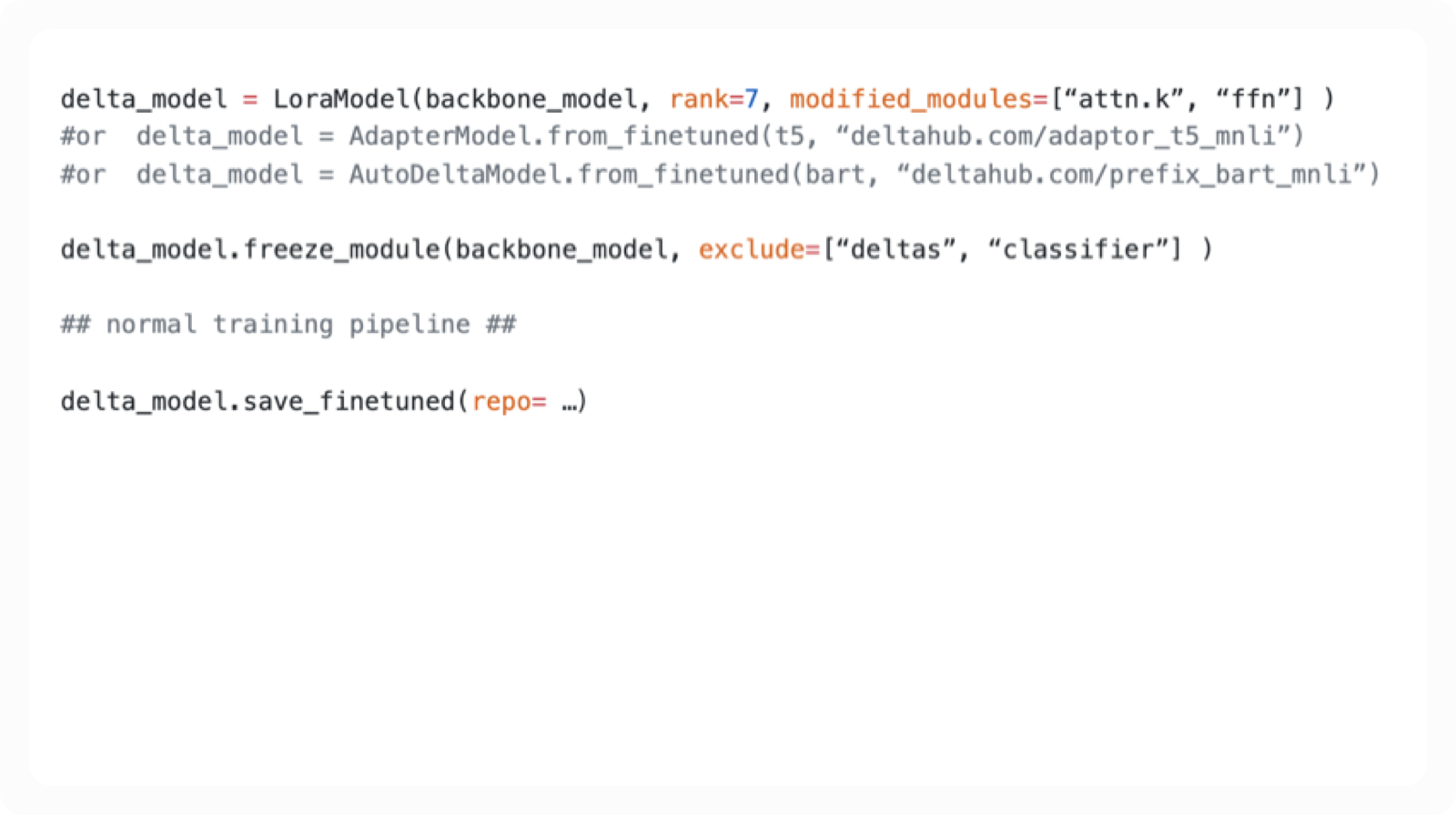
可视化操作


具体方法:
相同结构的图层被折叠(红色)
所有参数信息都保存,蓝色的可以调的,灰色是冻结的
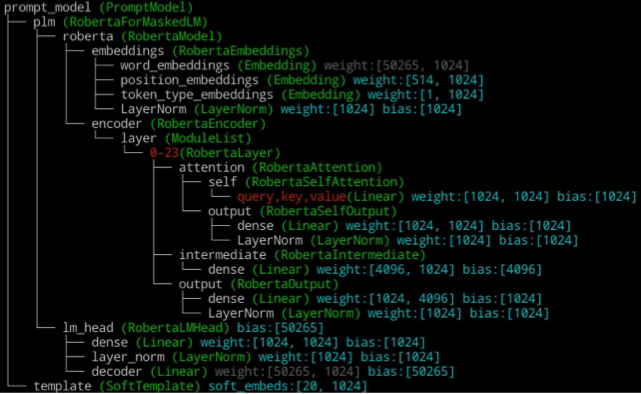
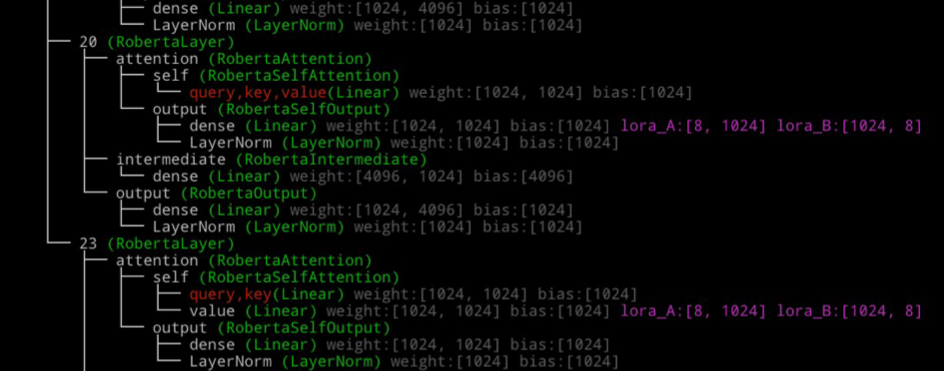
在任意层中插入增量模块。
1
delta model = LoraModel(backbone_model, rank=8,modified keys=["20.attention.output.dense", "23.attention.self.value"])
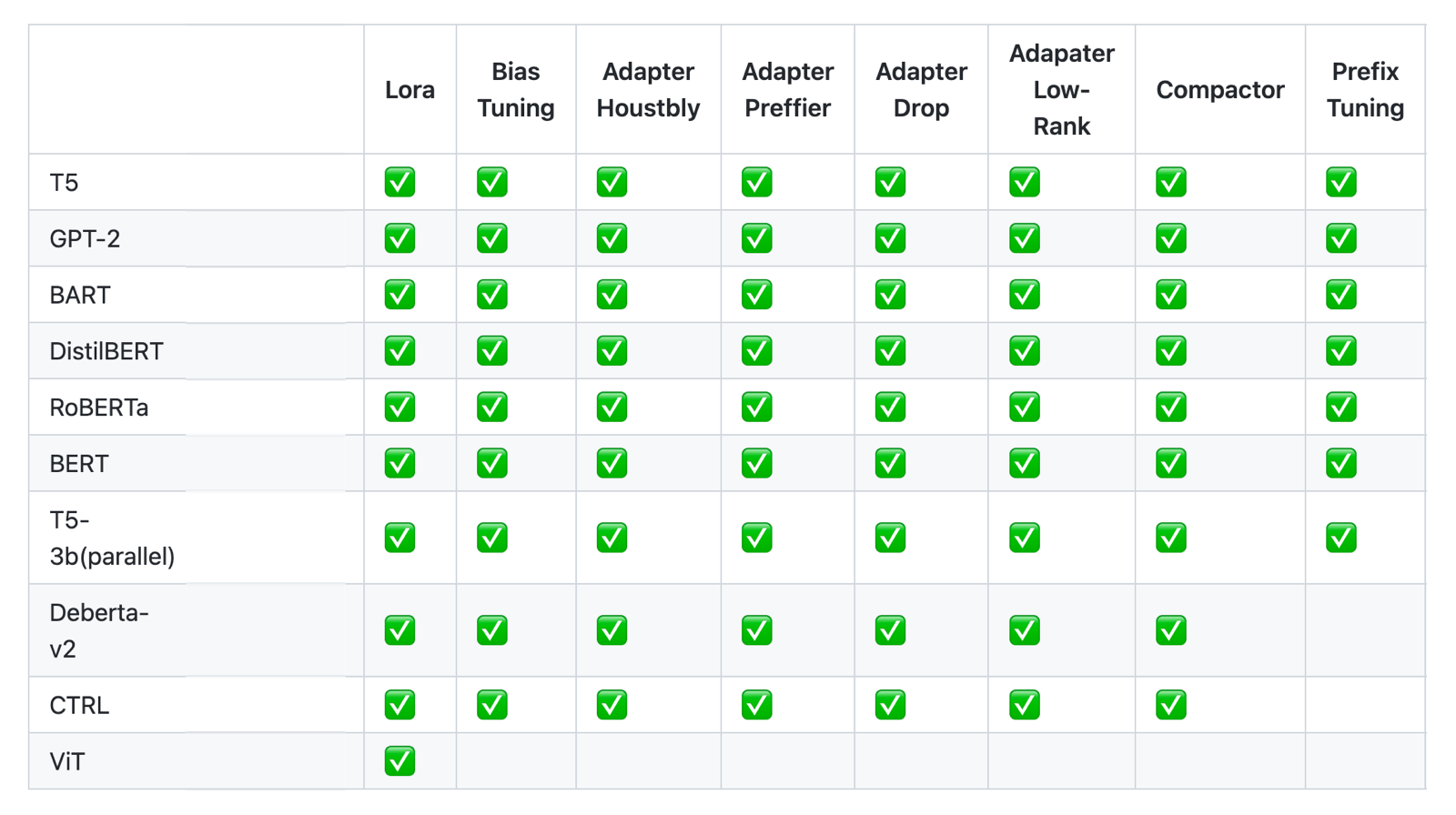
OpenDelta模型支持
OpenBMB模型仓库
ModelCenter
大模型仓库。ModelCenter基于BMTrain工具实现了一系列预训练语言模型,支持高效、低成本、可扩展性强的模型微调及分布式训练。
ModelCenter 实现了基于 BMTrain 后端的 PLM(预训练语言模型)
ModelCenter-github,ModelCenter’s Documentation
优点:
- 更高效的显存利用:我们的实现可以将显存占用降低数倍,进而使用更大的 batch-size 对 GPU 的计算能力进行更充分的利用。
- 易于使用:相比 Deepspeed, Megatron, ModelCenter拥有更好更灵活的封装,且配置 Python 环境简单, 训练代码与 PyTorch 风格统一。
- 以低资源实现高效的分布式训练:在 OpenBMB/BMTrain 的支持下,我们能够轻松地将 ZeRO 优化扩展到任何 PLM,并优化通信和时间调度,以实现更快的分布式培训。
- 性能强大:与流行框架对比,搭配BMTrain的模型表现惊人。

支持模型:
CPM-1[paper]
CPM-2[paper]
BERT[paper]
- bert-base-cased
- bert-base-uncased
- bert-large-cased
- bert-large-uncased
- bert-base-chinese
- bert-base-multilingual-cased
- kv-plm
RoBERTa[paper]
- roberta-base
- roberta-large
T5[paper]
- t5-small
- t5-base
- t5-large
- t5-3b
- t5-11b
- t5-v1_1-small
- t5-v1_1-base
- t5-v1_1-large
- t5-v1_1-xl
- t5-v1_1-xxl
- mt5-small
- mt5-base
- mt5-large
- mt5-xl
- mt5-xxl
- mengzi-t5-base
- flan-t5-small
- flan-t5-base
- flan-t5-large
- flan-t5-xl
- flan-t5-xxl
GPT-2[paper]
- gpt2-base
- gpt2-medium
- gpt2-large
- gpt2-xl
- wenzhong-gpt2-3.5b
GPT-J[paper]
- gptj-6b
Longformer[paper]
GLM[paper]
- glm-10b-zh
ViT[paper]
LLaMA[paper]